
Here’s how to locate relevant information on websites and databases that aren’t indexed by traditional search engines. Discover the features of deep internet search engines and find out what type of information each one searches for.
Traditional search engines like Google and Yahoo are great tools for finding information on the internet. Yet, despite the vast amount of data readily available with a simple search query in one of these search engines, it pales in comparison to the amount of information on the Internet that is un-searchable. The so-called ‘deep web’ is basically made up of databases and websites that aren’t indexed by sites like Google . Exploring the depths of the deep web isn’t as easy as searching the surface web, but there are a few search engines that are designed to tackle this challenge. Most focus on organized collections of information, including university libraries and scientific databases.
Infomine
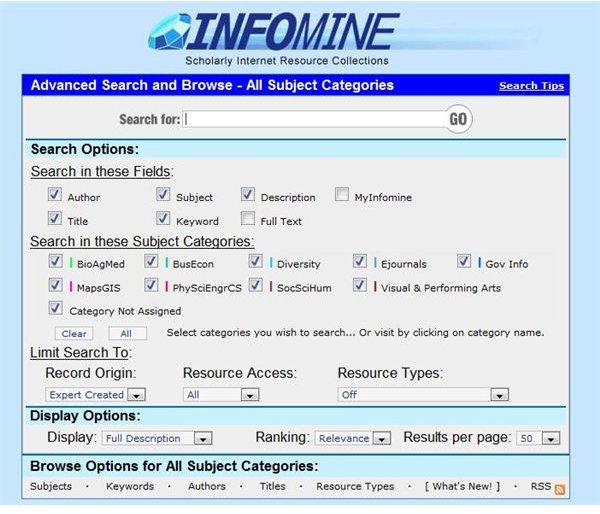
Begin your search of the deep web with Infomine . This search engine delves into several categories including medical sciences, business, maps, engineering, math, and social sciences. It is designed primarily for university research, and it searches for information stored in databases, electronic journals, electronic books, mailing lists, and online card catalogues. Some of the advanced search features include the ability to filter results by keyword, subject category, resource type, title, and author. This search engine was built collectively by several schools including the University of California, California State University, University of Detroit - Mercy, and Wake Forest University.
Deep Web Technologies

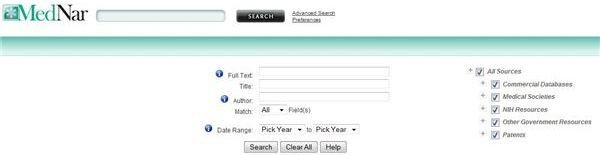
Deep Web Technologies is a deep web search company that designed several search engines. MedNar is one of them, and it displays results from over 60 medical collections through a federated search. This is a type of search where the user enters a single search query and the engine submits the query to several other search engines. The results of each engine is filtered and collated to create one authoritative results page. BizNar is a similar search engine, and it searches for business related data.
Scitopia is another engine powered by the federated search design of Deep Web Technologies. It searches through 3.5 million documents published by scientific societies and government.
The WWW Virtual Library


WWW Virtual Library is the oldest catalogue of the web in existence. It contains pages of links to sites about a specific topic. Most are posted by experts in each field. The site is broken up into several categories including agriculture, law, computer science, education, and international affairs. Since the site is run by volunteers, there are many links which may not have been updated since they were initially posted. That’s the downside of being the oldest existing web catalogue.
IncyWincy
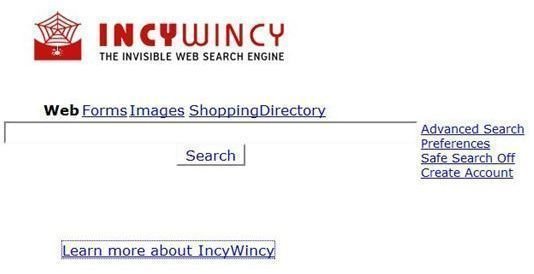
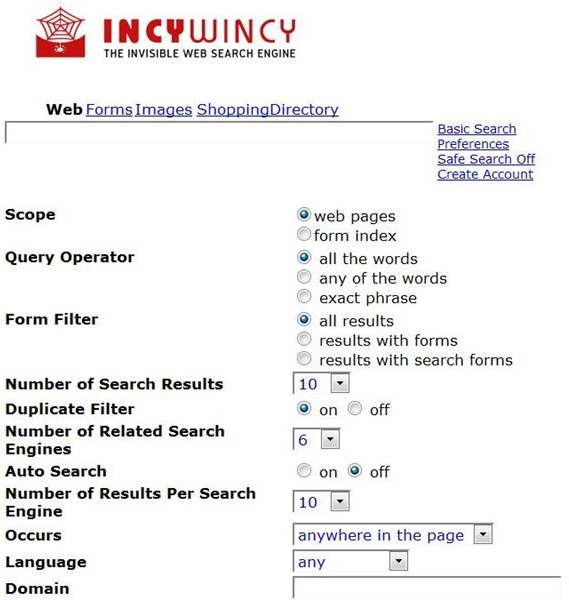
Another search engine that scours the deep web is IncyWincy . It contains over 200 million pages in its index. You can set IncyWincy to search the web, forms, images, directories, search engines, or meta searches . An unique feature of this engine is that as it indexes web pages, it also identifies search engines. Then, it uses them to conduct searches and examines the results from those search engines. You can even set alerts for results derived from a specific search engine. IncyWincy runs on Net Research Server (NRS) 5.0, which was developed by LoopIP.
Intute
Intute is a search engine designed to find the best educational resources for research and study. It was built by several English universities including University of Birmingham, Heriot-Watt University, and University of Nottingham. You can search by keyword, title, or description, and the results can be narrowed down to a particular subject, resource type, or country of origin. The topics available through this search engine include architecture, biological sciences, geography, and medicine. Some of the materials this search engine browses through include case studies, law reports, specimen databases, think tanks, and patents.
The next time you have to conduct research on the internet, search a little deeper with one of the deep internet search engines mentioned above. You will find relevant resources that provide insight into a variety of fields. For medical research, consider using the MedNar search engine. For arts and humanities, try the WWW Virtual Library. These search engines are designed to find information that is available through the internet, but don’t show up on a typical search results page. Unless you know the exact web address of the site the information is stored on, it would be nearly impossible to find it online without these search engines.
Reference
- Infomine - https://infomine.ucr.edu/
- Deep Web Technologies - https://www.deepwebtech.com/product-trial/try-it-now/
- The WWW Virtual Library - https://vlib.org/
- IncyWincy - https://www.incywincy.com/
- Intute - https://www.intute.ac.uk/
Image Credit - Screenshots taken by author.


