If you like reminiscing on the good old days of the Internet, then the Wayback Machine search engine may be your best friend. It is the proverbial time machine for the Internet. Find out how to take a nostalgic trip back in time with the Wayback Machine.
All about the Wayback Machine
The Wayback Machine search engine is an archival project that allows the retrieval of past versions of websites. Some websites have archived versions dating back to the year 1996. The Internet Archive , a non-profit digital library organization, currently maintains the Wayback Machine.
The Wayback Machine uses Alexa Internet’s web crawling service. Sites within DMOZ’s Open Directory project are crawled for archival. In addition, sites visited by those using an Alexa toolbar in Internet Explorer are submitted for archival. Finally, using the show related links feature in Internet Explorer also prompts Alexa Internet to crawl the website.
Since the Wayback Machine depends on a web crawler to find and index web pages, it is subject to site rules defined in the website’s robots.txt file. The robots.txt file includes instructions for what a web crawler should and should not index. Entire websites can be excluded from web crawlers using the robots.txt file.
Using the Wayback Machine
Since the Wayback Machine is designed similarly to other search engines, it is inherently easy to use for those who are accustomed to Internet searches. On the Wayback Machine’s website, enter the website address, or URL, for which you would like to find archived versions. Then, simply click the Take Me Back button.
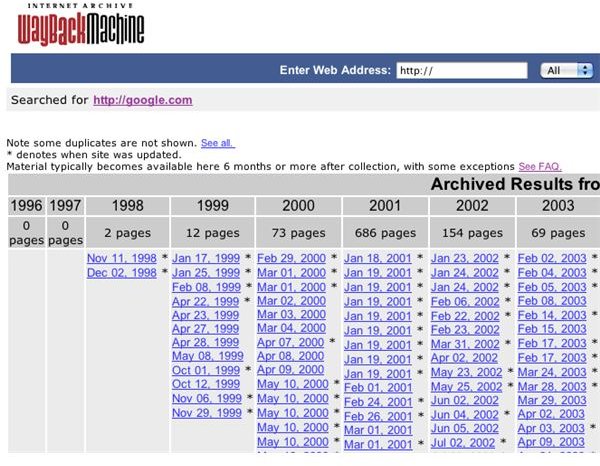
Not all websites on the Internet are archived in the Wayback Machine. If the website you entered is recognized by the Wayback Machine, a table of archived versions will appear. The table is organized by year, with each column representing a calendar year. All of the archived versions of the website for a particular year are listed in within that year’s column. To view an archived version, simply click the date.
When you view an archived web page, all of the images and links typically refer to the archived version. Therefore, clicking a link on an archived page will attempt to retrieve the archived version of that page as well. Sometimes the link will lead to an archived version on a different date. The Wayback Machine attempts to pull an archived version of the page closest to the date of the page you are visiting. If there is no archived version available, you will usually be directed to the live version of the website.
Potential Problems and Issues
The Wayback Machine’s archive is not entirely comprehensive. Some websites are not archived within the Wayback Machine. On archived web sites, some images and other rich media may not be available. Additionally, links on an archived page may no longer work, or may not have an archived version. If there is no archived version of a link, then the Wayback Machine will usually send you to the current version of the link.
Additionally, the Wayback Machine search engine may return an error if it is under heavy traffic, or if there are temporary data issues. This is common during peak traffic hours. Sometimes a server hosting a set of archives is offline. If the archived page that you are requesting is on an offline server, an error will be returned. If you receive an error when searching for an archived website, wait a few minutes and try again.


