CPUs have more cores than ever, but the software to take advantage of them has yet to arrive, and processor clock speeds have platuead because of heat and power issues. To unlock the potential of multi-core processors in mainstream computing, software development requires new tools and techniques.
What Is Parallel Processing?
People spend a lifetime working on questions of parallel computing, so we’re obviously keeping things brief, and simplifying. If we compare a processor to a factory, a single core processor is like a factory with one assembly line. More cores in the processor represents more assembly lines, which run in parallel.
To achieve the same performance output, either in a factory or processor, you can either upgrade the assembly (processing, in computing terms) line to run faster, or add another line. For about two decades, processor improvements have been based on turning up the clock speed, making the single pipeline able to handle more instructions per second.
The Pentium IV saw the last great increase in clock speed over the previous generation of processors. Its final iteration, the Prescott, was to have been available at up to 3.4 GHz, but those were hard to find because of reliability issues. It was widely believed that the power requirements led to so much heat that the chips couldn’t cope.
Power, Heat, and Memory Walls
A plateau was reached at a little above 3 GHz. The faster a chip runs, the more power it uses, and the more heat it generates. Prescott reached the point where normal cooling solutions, ones that could be placed affordably in mainstream computers, couldn’t keep the CPU in its operating envelope. Factor in the green and mobile computing trends, and cranking up the speed and watts was no longer an option with ecology and battery life to worry about.
Furthermore, CPUs were getting faster much more quickly than memory was. The larger this difference became, the more dramatic the performance hit every time the CPU had to access main memory. The solution was to put ever larger caches onto the CPU. Cache is a very small amount of memory housed in the CPU chip, and running at the CPU’s clock speed.
Using the cache instead of main memory whenever possible helps with the RAM/CPU speed difference, but a larger cache takes up more room. That room could have otherwise gone to more processing power. With that and the heat/power question, the assembly line was running as fast as practically possible, so it was time to start another line.
Parallel Problems
Adding lines, like adding cores, introduces complexities that don’t occur when speeding up a single one. The jobs that need to be done have to be divided to make sure things are being done as efficiently as possible. Otherwise, cores sit idle, or worse still, things get done in the wrong order, or twice, or not at all.
Dividing the work results in a certain amount of overhead. People at the different lines often need information from someone at another line: the time they take communicating eats into the time they can spend processing. Even if they can look up the information they need without disturbing the people on the other line, they have to run around and look for it, called cache snooping in CPU terms.
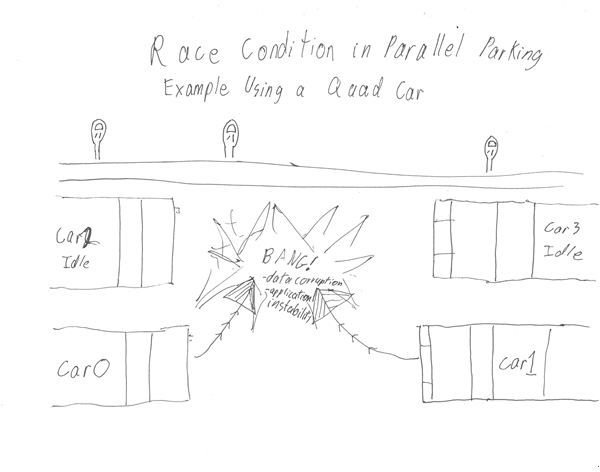
The largest problems occur if two cores are doing different things to the same data at once, called a race condition. If one core is trundling through a database applying a currency conversion to all the numbers in several columns of several tables, and another is calculating column totals in the same tables, they can make quite a mess.
To prevent this, one process can lock the data it is using. This solves the problem, though at the cost of having the other core sit idle. If you lock every step of a program, it runs serially, not in parallel. Even if the work is processed by several cores, it will take just as long if they are each waiting for the previous steps to be completed. Actually, the overhead means it can take longer.
Up Next: The Slow Parallel Road to the Mainstream: When will your dual or quad core benefit from parallelism?
The Long Parallel Road
Because of the complexities involved, the overwhelming majority of software applications run on a PC don’t take advantage of parallel hardware. Initially, it was restricted to super-computers and High Performance Computing, where universities, hospitals, and large business could throw massive resources into developing hardware and software for a specific kind of problem.
Many of these problems are based on the arithmetic manipulation of huge data sets, so there was a head start in implementing parallel solutions to solve them. Genetics research, for instance, involves statistical and combinatorial analysis of massive databases. It’s relatively easy to break this task down into similar pieces that can each be done independently on different parts of the information, called data parallelism.
Servers are also good candidates for parallel solutions, since they deal with huge volumes of tasks, but they are generally small and very similar to one another. Also, servers have had several CPUs for many years now, so their applications are already optimized for several threads. Home and office computers, however, are a totally different kettle of fish.
Parallel and Mainstream at Cross Purposes
The HPC applications have migrated from super-computers to high-power workstations, and in very demanding professional applications, where there is a lot of number-crunching going on, like in 3D rendering, multi-core processors are put through their paces. This is obvious when a Core i7 CPU, with four cores and Hyper Threading, therefore running eight threads, runs workstation-type software .
But day-to-day tasks like web browsing, and even demanding games, don’t spread out well over several cores. For one thing, your computer never knows what you will do next. You could be checking email while your virus scanner is working away on another core. Everything is hunky-dorey until you follow a link to a Flash video, and the operating system needs to decide how to divvy up the new processes.
A super-computer might be left to run on a problem for months, and a workstation will regularly have a couple of hours or a weekend to churn on something. Obviously, getting mainstream computing tasks to take advantage of several cores is no mean feat. But Intel, Microsoft, and Nvidia all want to help.
The Parallel Push
Microsoft, which supplies most of the world’s operating systems, is keen on parallelism, as are Intel and AMD. The most interesting of parallel’s proponents, however, is Nvidia. By virtue of their graphics processors, which are made up of dozens of stream processors , Nvidia (and AMD) arguably are already implementing parallel computing to a far greater extent than Intel (or AMD’s CPU side.)
Coupled with Intel’s degenerating relationship with both AMD and Nvidia, it appears there will be a lot of jostling on the way to mainstream parallel computing. We look at how Nvidia and Intel are positioning themselves on the parallel battlefield here . And it looks like their parallel paths are going to collide.