This is the final article in the series on data security incident management. This focuses on how to manage data security systems and the causes and effects of data systems or network system failures in a company.
Improve Overall Data Security
The activities related to this step take place after all other steps in data security are complete, and all affected data or network systems are restored. The purpose of the this data management step is to review the security incident and determine how to prevent the same type of successful data or network attack in the future as well as to identify areas for improvement to facilitate faster response and better business impact mitigation. Using documents created during the Detect, Contain, and Eradicate steps, the IRTs seek to answer the following questions:
- What happened to corporate data or network systems?
- What was supposed to happen to these information systems?
- What are the differences, or gaps, between 1 and 2?
- What are the reasons for the differences?
- What data security controls failed or were missing in the areas of people, process, and technology?
- What are the lessons learned?
The process of answering these questions and the development of an Action Plan to improve incident detection and response are the elements of an After Action Review, or AAR.
Cause and Effects of Data Security Threats
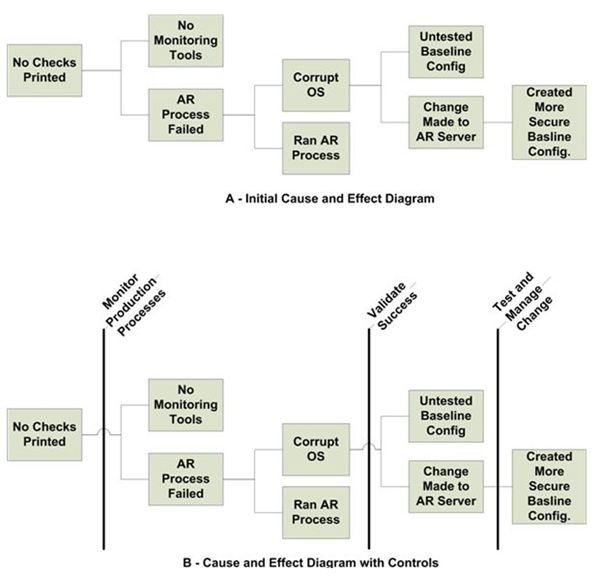
One of the easiest and most effective methods of tracing the chain of cause and effect is the use of a Cause and Effect Diagram. There are different approaches to mapping cause and effect. Figure 1 depicts a variation on an approach documented by Dean L. Gano (1999). Figure 1A is a basic diagram with no controls specified. Figure 1B is the same diagram with controls. Let’s step through the process.
-
Begin at the end. To create a Cause and Effect Diagram, begin at the primary effect on the left and work to the right. The
Advertisementprimary effect is the business impact caused by the data security or network incident. In our example, it is described as “No Checks Printed.”
-
Ask why. For each effect identified, ask the question, “Why did this happen?” In Figure 1A, the answer is that the “AR Process Failed”; this is the action that created the effect. Notice that there is another box paired with the action, “No Monitoring Tools.” This is a condition statement. In many cases, an effect is caused due to an action occurring in the presence of a specific condition. This isn’t always the case, but be sure to explore the possibilities carefully. This is considered a condition in this case, because identifying the data security or network failure earlier may have provided opportunities to recover and run the checks on time.
Advertisement -
Proceed until you reach the point of ignorance or irrelevance. Continue to ask why until you arrive at a cause/condition pair where any information about what caused them may be unknown or irrelevant when assessing how to prevent the chain of events under analysis. That is where you stop. There is no hard rule for how to identify this point. The IRT members will have to make that determination based on the data provided and their knowledge of the business and the technical infrastructure.
-
Tell the story. Once you complete the diagram, walk through it from right to left while describing the chain of events leading up the primary effect of the data security incident. Document this description in an incident report.
Advertisement -
Identify failed or missing controls. As you walk through the diagram, identify where existing controls exist and why they failed. Also identify points in the chain where a new data security control might serve to stop the progression of cause and effect instances leading up to the primary effect on the company network. Annotate both existing and proposed controls in your diagram. Figure 1B is one way you might accomplish this.
Example of Documenting a Data Security Threat
Let’s walk through our example and see how the story might be documented.
The security team created a more secure baseline configuration. Without testing the new configuration, a change was made to the AR Server. This resulted in a corrupt operating system on the AR Server. The corrupted state of the system went undetected since no validation process was executed to ensure proper operation of the AR Server. When the operators ran the AR process in the corrupted environment, the AR process failed. Since there were no automated tools or manual checkpoints to monitor the health of the AR process, the operators were unaware that the process had stopped. Because no action was taken that would have resulted in a successful data recovery of the AR system, no checks were printed.
Notice that there is no assignment of blame anywhere in this description. The fastest way to make your AARs ineffective is to make it a forum for finger-pointing. The AAR process should be professional and objective, seeking only the facts so that improvements can be made.
As we told the story represented by our example Cause and Effect Diagram, it was easy to see the points at which controls were missing. The following is the story again with text in bold that point to missing controls.
The security team created a more secure baseline configuration. Without testing the new configuration, a change was made to the AR Server. This resulted in a corrupt operating system on the AR Server. The corrupted state of the system went undetected since no validation process was executed to ensure proper operation of the AR Server. When the operators ran the AR process in the corrupted environment, the AR process failed. Since there were no automated tools or manual checkpoints to monitor the health of the AR process, the operators were unaware that the process had stopped. Because no action was taken that would have resulted in a successful data recovery of the AR system, no checks were printed.
If you compare the missing controls identified in the second iteration of the story, you’ll see that they are closely related to the conditions identified in the diagram. This is no accident. In most cases, the most effective way to stop an unwanted chain of events is to eliminate one or more unwanted conditions. In our example, no data security controls existed. We inserted recommended controls in Figure 1B we will use to create our action plan.
Data Security Action Plan
An action plan is the final product of an incident response. In our example, I would recommend two items for the data and network action plan. First, I would plan for the implementation of a Change Management Process. Change management is a good way to implement change into a production environment while ensuring a low probability that the change will interrupt data or service delivery. If the engineers in our example followed change management best practices, they would test the change before moving it to production. Further, they would execute a validation process to make sure the AR Server is functioning properly. If the change caused a problem, the engineers would execute a back out process to return the server to its original state with data intact. All of these processes should be documented and tested BEFORE the change is made to production.
Second, I would plan for the implementation of either manual or automated processes to track the execution of production jobs. This is another best practice that was missing from our example environment.
This is a very simple representation of how to approach an AAR. Your organization’s culture, management hierarchy, and the nature of each data security incident will affect the way you approach security incident reviews.
Data Security Incident Management Series Summary
Data security Incident management is a key part of an organization’s efforts to maintain accurate, on time service and data delivery. Building a data security incident management capability requires careful preparation, complete documentation, and the formation and training of IRTs. Testing incident response scenarios is just as important as testing corporate data loss recovery from potential declared disasters.
The steps in responding to an incident are detection, containment, eradication, and management. The use of cause and effect diagrams to map the course of an incident and the efforts to recover from its effects is an important tool for identifying weak or missing controls. The use of a cause and effect diagram, as part of an overall AAR, leads to the creation and execution of an action plan designed to strengthen an organization’s ability to prevent significant adverse business impact.
Works Cited
Gano, D. L. (1999). Apollo root cause analysis: a new way of thinking. Apollonian Publications.
This post is part of the series: Security Incident Management
in this series, I provide an overview and recommendations related to responding to a security incident. Effective incident management is critical when attempting to mitigate damage from a breach, system failure, data leakage, etc.
- The Data Security Incident Management Process: Policies, Teams, and Communication
- Preventing and Containing Data Loss by Detecting and Analyzing Data Security Issues
- Reducing the Damage Caused by Network Security Threats and Identifying Attackers
- Recovering Corporate Data After a Data Security Attack
- Challenges of Managing Data Security: Causes and Effects of Data System Failures