Learn about RAID Levels and RAID Data Recovery
RAID Overview
RAID (Redundant Array of Independent Disks) generally refers to dividing data across multiple hard drives. This is done for two reasons:
survivability and performance. RAID makes data survivable because when one drive fails or loses data, the other drives in the set either contain the lost data or are able to reconstruct it, meaning that an individual or business is no longer vulnerable to hard drive failure. This configuration has the additional benefit of improved performance, making disk reads and writes faster in most situations. Raid data recovery is usually possible in the event one drive fails.
Although a RAID consists of two or more drives, the computer operating system reads and writes to the RAID as if it were one drive. Within the RAID, redundancy is carried out through mirroring, striping, and parity (the ability to correct errors). Different implementations of these methods are organized into several categories, known as RAID levels. As we review these different levels, you will gain an understanding of how data files are copied on a raid hard drive.
Image Credit: Wikimedia Commons/Cburnett
RAID Levels
Although seven levels of RAID are commonly defined, almost unlimited variations can be created by combining different elements from each. For the purpose of this discussion, we will focus on the defined levels in order to understand how raid data recovery works.
RAID 0 doesn’t really produce any redundancy (if one drive fails, the data on the RAID is lost), although it is useful for performance purposes. It uses the technique called striping to spread data blocks across multiple drives. Because data is striped across different drives, the computer can access the data twice as fast in a two drive configuration. RAID 0 provides for twice as much data to be written in the same amount of time. RAID 0 achieves this performance increase without reducing the combined amount of storage space. The lack of RAID data recovery makes RAID 0 unappealing to those looking for the ability to survive a hard drive failure.
RAID 1 works without striping, so it doesn’t have the same performance increases as found with RAID 0. Using a technique called mirroring, RAID 1 maintains an identical copy of the main (or “active”) drive at all times on the “mirror” drive. If the active drive fails, it can be removed and the mirror drive can be set to operate in its place. Disadvantages of RAID 1 include the loss of hard drive space (the storage capacity is that of the smallest drive), the lack of performance improvements, and the time it takes to change from the active to the mirrored drive in the event of failure.
RAID 2 requires at least three drives. Synchronization of disk rotations is achieved and a stripe is created so that every subsequent bit is placed on a different disk. One disk is used to store parity information that can be used to correct errors. If one drive fails, the disk array continues to operate. Because the system writes data across multiple disks, performance gains are realized and the use of a parity drive enhances survivability.
RAID 3 provides striping of bytes so that every next byte is placed on the next drive. Parity is managed on a dedicated drive to provide survivability in the case a drive goes bad. The space of all the drives in the RAID combine (minus the parity drive) is combined to make the storgage capacity of the RAID cumulative.
RAID 4 has a dedicated drive for parity and stripes blocks across the disks. In this array, each disk operates independently so I/O operations can be performed in parallel, although transfer rates can be slowed due to the dedicated parity. RAID 4 requires at least three drives and can survive the failure of one.
RAID 5 stripes distribute data blocks across the disk array. This type of raid also distributes parity information across the array, resolving the throughput problems associated with dedicated parity configurations. If a drive fails, the array continues to operate until a replacement is installed. When the drive is replaced, the parity information is used to reconstruct the data that belongs on it. If a second drive happens to fail before the first drive is replaced, data loss can be experienced. Although RAID data recovery is most reliable with distributed parity arrays, they often are cost prohibitive when trying to implement.
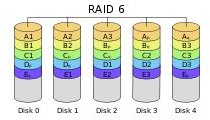
RAID 6 features double distributed parity, meaning that the array can operate even if two drives have failed. These arrays require a minimum of four drives and can grow to massive sizes. The double parity feature of RAID six buys time for administrators to replace a drive without risk of a second drive failure that would doom other RAIDs. The increased survivability or RAID 6 makes it appealing for use in mission critical applications and 24/7 operations. With RAID 6 there are significant performance gains, although those gains are usually erased while the array is recovering from a drive failure.
RAID Summary
RAIDs can take the form of any of the seven configurations or they can borrow from different levels to form a hybrid. Also, RAIDs can be configured as drives in larger arrays, making the possibility for very large and very costly data storage configurations. Now that you have an understanding how data files are copied on a RAID hard drive, you can make the best choice of which kind of RAID you should deploy.